
Hey there, fellow machine learning enthusiasts! As I embark on this fascinating journey into the world of machine learning, I’ve quickly come to realize that some areas of mathematics are simply too important to bypass – and right at the top of that list is linear algebra.
When I first heard about it, I thought, “Why would a topic that sounds so math-heavy be crucial to something as cutting-edge as machine learning?” Turns out, linear algebra isn’t just a bunch of abstract concepts; it’s the very backbone of many algorithms and processes we adore in the ML world.
With that, I decided to pick this subject up and, to be honest, I was blown away by its significance. I felt compelled to share my findings, and that’s what led to this piece. If you’re like the younger me, wondering why on earth you’d need to brush up on vectors and matrices or if you’re a professional considering a shift to machine learning, then you’re in the right place.
Stick around, as we delve into the captivating realm of linear algebra and explore its indispensable role in our machine learning journey.
Why Study Linear Algebra for Machine Learning?
I’ll admit, when I first started my machine learning journey, I wondered: “Do I really need to get tangled up in all this math, especially linear algebra?” Ever since college, I hated math and calculus so I was hesitant. However, the more I delved into linear algebra, the clearer it became that yes, indeed, I need it. And here’s why.
Imagine a world where machine learning is like building intricate structures, much like LEGO constructions. In that world, vectors, matrices, and linear transformations are the individual LEGO pieces. These mathematical constructs are foundational. Without them, we’d struggle to represent data, let alone work with it.
Diving into linear algebra can initially feel like learning a new language. And in many ways, it is. But with every language comes the beauty of expression – in the context of machine learning, this ‘language’ lets us express data and operations in profoundly effective ways. Let’s unpack some of these essential “words” and “phrases.”
- Vectors: Picture standing at the edge of a vast field, with the urge to reach a distant tree. The direction you choose and the distance you’ll cover can be represented as a vector. In a more machine learning-esque setting, think of vectors as arrows pointing from one data point to another in a space. They have both direction and magnitude, and they encapsulate the core idea of representing information in a structured way. Whether it’s the features of a dataset or the weight updates in a neural network, vectors are our guiding lights.
- Matrices: Remember those days when you tried to organize your thoughts or tasks in tables? Matrices are a bit like those tables but supercharged. They’re grids filled with numbers, representing multiple vectors. Think of it as a toolbox holding various tools (vectors). Matrices are particularly crucial when we’re juggling vast amounts of data. They help us streamline operations, be it transforming data or training complex models. And just like how a well-organized toolbox can enhance productivity, understanding matrices can be a game-changer in handling data efficiently.
- Linear Transformations: Imagine working with a digital image. By zooming, rotating, or panning, you’re altering the view, right? Linear transformations do something similar for data. They’re about reshaping, rotating, or scaling data without losing its essence. It’s like taking our vectors and matrices and giving them a new perspective while keeping their foundational truths intact.
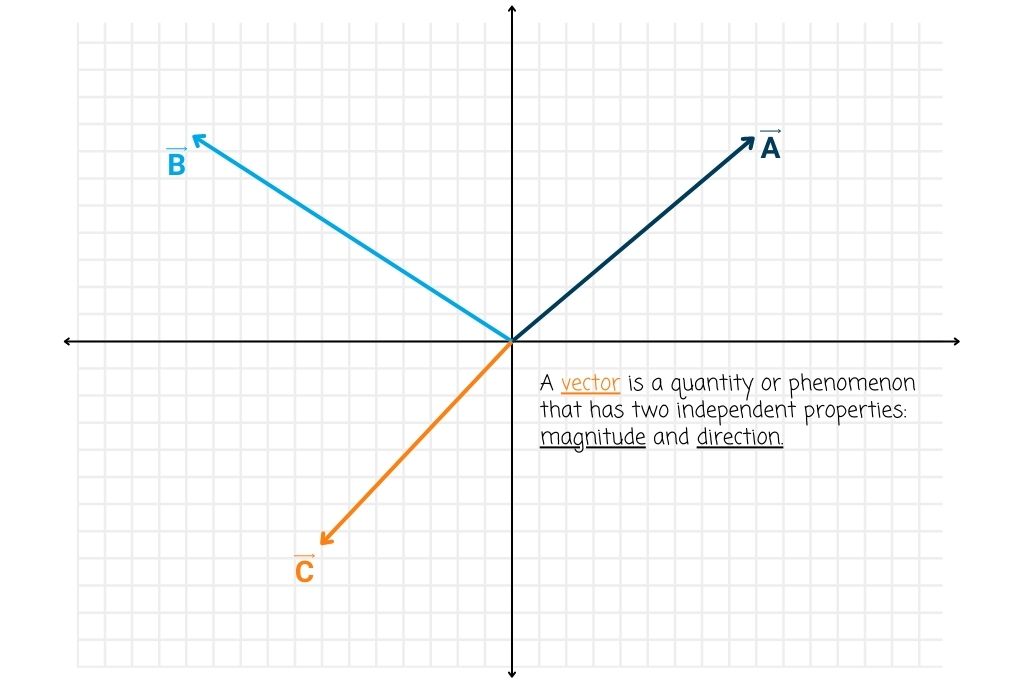
Understanding linear algebra is so foundational to machine learning that it’s akin to understanding the basic rules of a game. Sure, you can play without knowing them, but your game becomes stronger, more strategic, and a lot more fun when you do. And in the vast, evolving landscape of machine learning, having a solid grasp on linear algebra ensures you’re not just playing the game, but mastering it.
When it comes to the operations in linear algebra, there’s a rich tapestry of them. From adding and subtracting vectors to multiplying matrices, these operations are the building blocks for more advanced algorithms in machine learning. And, much like how the basic grammar rules in a language form the bedrock of more complex sentences and expressions, mastering these operations lays the groundwork for intricate ML models and systems.
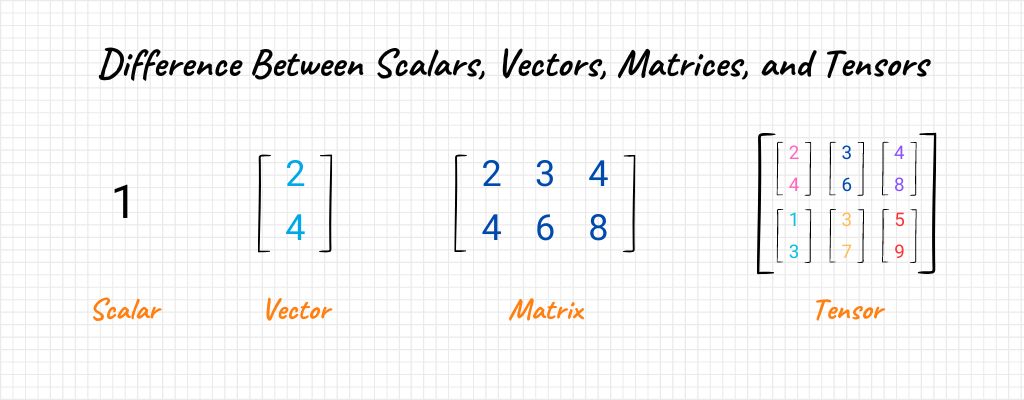
Applications of Linear Algebra in Machine Learning
Linear algebra is not just a theoretical study; its applications in machine learning are both vast and profound. By connecting mathematical concepts with machine learning algorithms, we can truly appreciate the beauty and utility of this domain.
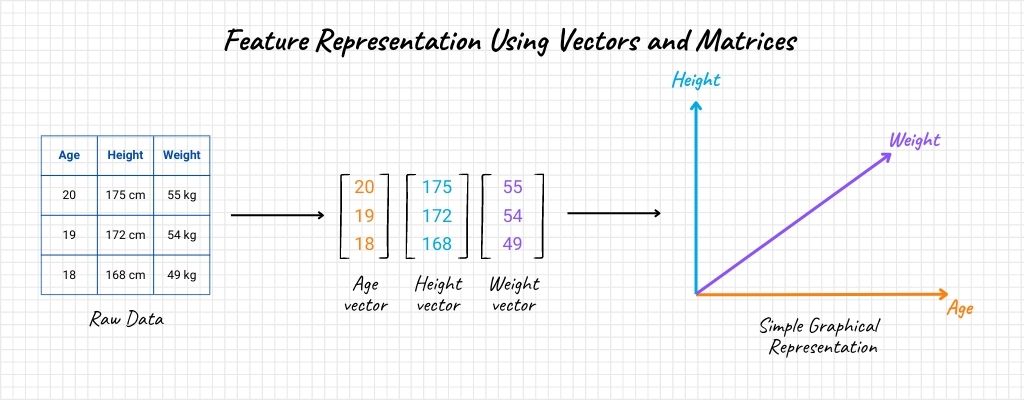
Feature Representation using Vectors and Matrices
Every data point in machine learning can be seen as a vector in a high-dimensional space. If we consider an image, for instance, its pixel values can be unraveled into a long vector. Likewise, if you have a dataset with multiple features, it can be represented as a matrix, where each row is a data point and each column corresponds to a feature.
Equation: For a dataset with \(n\) data points and \(m\) features, the matrix representation is \(M_{n×m}\).
Optimization and Gradient Descent
Machine learning models often need “tuning” to perform their best. This tuning is an optimization problem where we aim to minimize a cost function. Gradient descent, on the other hand, is a popular method, and it heavily relies on vectors to adjust the model’s parameters in the direction of the steepest decrease of the cost function.
Equation: The update rule for gradient descent is \(θ = θ – α ∇J(θ)\), where \(θ\) is the parameter vector, \(α\) is the learning rate, and \(∇J(θ)\) is the gradient of the cost function.
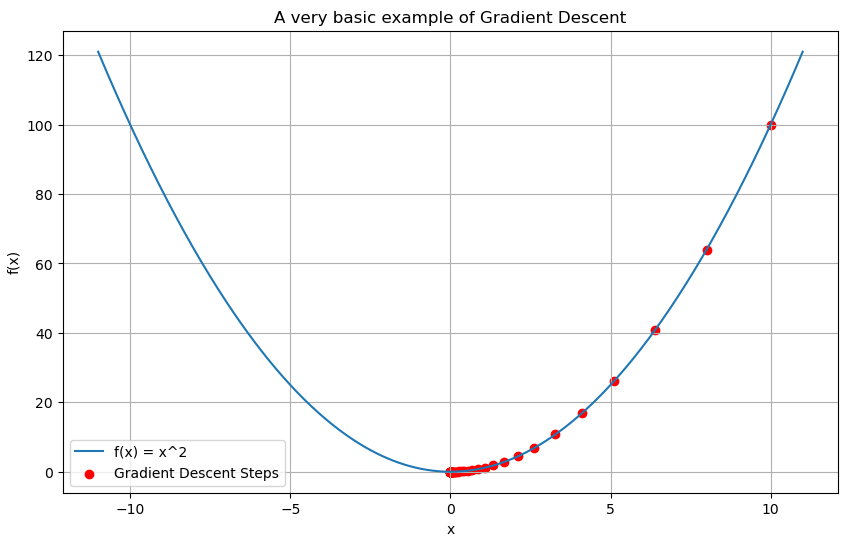
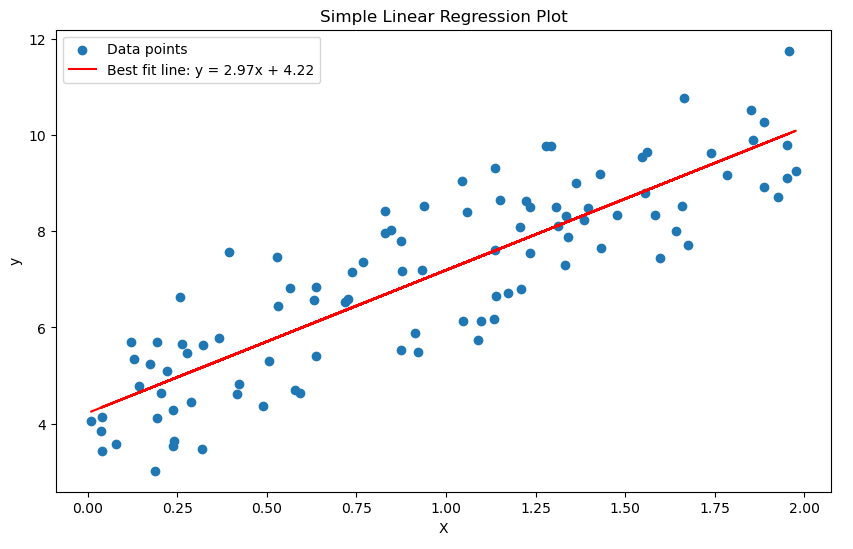
Model Training (Linear Regression, SVMs, etc.)
In linear regression, the relationship between features and target is approximated linearly. The weights or coefficients of the model can be visualized as vectors, making the prediction a dot product between input vectors and weight vectors. SVMs, on the other hand, use linear algebra to find the optimal hyperplane that separates different classes in the feature space.
Equation for Linear Regression: In a simple linear regression, where there is only one independent variable, the model can be mathematically expressed as:
\[ y = \beta_0 + \beta_1 x + \epsilon \]
Here, \( y \) is the dependent variable, \( x \) is the independent variable, \( \beta_0 \) and \( \beta_1 \) are the coefficients, and \( \epsilon \) represents the error term.
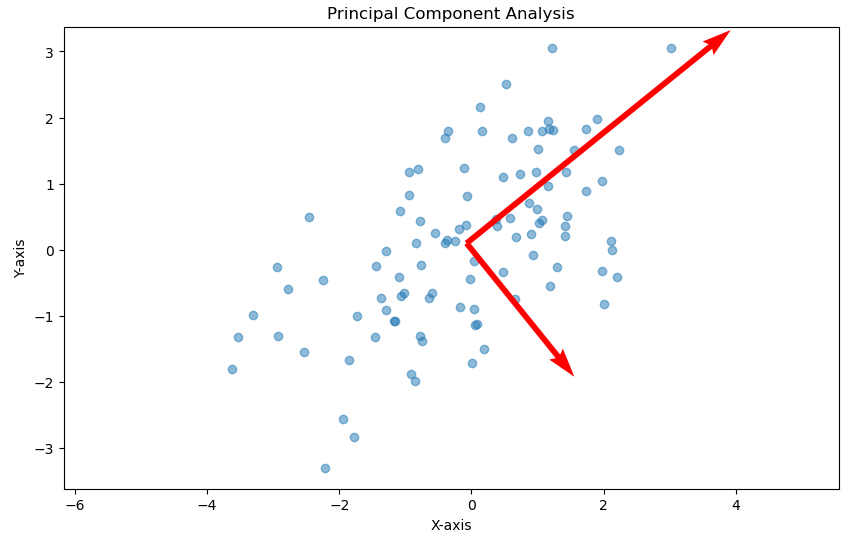
Dimensionality Reduction Techniques like PCA
High-dimensional data can be tricky to work with due to the curse of dimensionality. PCA (Principal Component Analysis) uses linear algebra to transform the original high-dimensional data into a lower-dimensional space while retaining maximum variance. It does this by computing eigenvectors (principal components) of the dataset’s covariance matrix.
Concept: The principal components (eigenvectors) dictate the directions of maximum variance in the data.
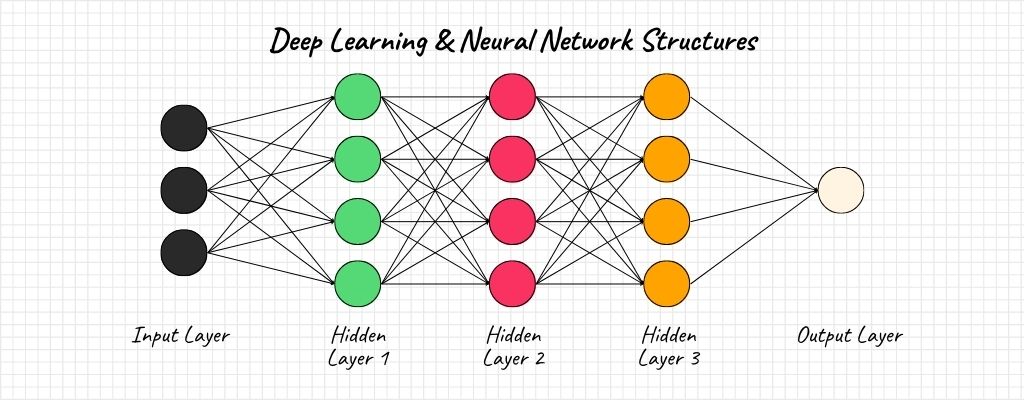
Deep Learning & Neural Network Structures
Neural networks consist of layers of interconnected nodes (or neurons). The input data, activations, weights, and biases in these networks are all represented using matrices. Matrix multiplication plays a pivotal role in propagating data through these layers, making linear algebra a cornerstone of deep learning.
Equation: For a layer’s output \(O\), given input \(I\), weights \(W\), and biases \(b\), we have \(O = I × W + b\).
By diving into these applications, it’s clear that linear algebra isn’t just an abstract mathematical field. It’s the scaffolding that holds the vast edifice of machine learning together, guiding us from foundational concepts to advanced implementations.
How to Learn Linear Algebra for Machine Learning
As I delved into the maze of linear algebra, I found myself both fascinated and occasionally overwhelmed. I mean, who hasn’t felt the weight of dense mathematical texts or the overweight of abstract concepts at one point or another? But trust me, with the right resources and approach, it’s an immensely rewarding journey. Here’s a compass to navigate your way:
Recommended Courses, Books, and Resources
Courses
- Khan Academy’s Linear Algebra Series: Ideal for those who prefer bite-sized lessons and visual explanations. This is actually my best recommendation to learn the basics of machine learning. The lessons can be taken even if you only allot 30 minutes per day. Also, the courses are well-structured and Sal’s explanations are easy to comprehend.
- FreeCodeCamp.org’s Linear Algebra Course: This course is more college-level than novice machine learning student level. However, what I love about this course is that it’s free and it provides you with more than what you need for machine learning. To be honest, I only finished this course because of the professor himself, Dr. Jim Hefferon, a professor of mathematics at St Michael’s College.
Books
- Linear Algebra by Dr. Jim Hefferon: This is the only book I ever read for linear algebra. This comes in conjunction with FreeCodeCamp’s linear algebra and is available for free download. As I’ve mentioned above, this is more like a college reference text but it’s very comprehensive even for beginners.
Resources
- 3Blue1Brown’s YouTube Series on Linear Algebra: Offers a visual intuition behind many core concepts, making them easier to grasp.
- Epic Math Time: Like 3Blue1Brown, this YouTube channel makes math easier to understand, from linear algebra and probability to differential and multivariable calculus.
Tips and Strategies for Learning
- Start with Why: Remember why you embarked on this journey. Knowing that linear algebra is the backbone of machine learning can be a powerful motivator.
- Mix Theory with Practice: While understanding theoretical concepts is vital, try to implement them too. Platforms like MATLAB or Python’s NumPy library allow for hands-on matrix and vector operations.
- Join Communities: Engaging with peers can clear up confusions and keep the learning momentum. Forums like Linkedin groups and subreddits focused on math and machine learning can be invaluable.
- Consistency is Key: Linear algebra is vast, but it’s not a sprint; it’s a marathon. Dedicate a little time each day, and you’ll be surprised at the progress you make.
- Relate to Real-World Applications: Always try to connect what you’re learning with real-world machine learning scenarios. It’ll make abstract concepts more tangible.
Embarking on the linear algebra trail with the aim of mastering machine learning is an expedition, one filled with ‘aha!’ moments and occasional hurdles. But with the right resources and mindset, you’ll not only grasp the subject but truly appreciate its beauty and utility in the ML universe.
Case Studies and Examples
The beauty of linear algebra, especially in the realm of machine learning, truly shines when you witness it in action. During my own expedition into this subject, I came across several instances where abstract matrices and vectors transformed into tangible solutions to real-world problems. Let’s delve into some of these case studies:
Applications of Linear Algebra in Machine Learning
- Image Compression with Singular Value Decomposition (SVD): Every digital image can be broken down into matrices of pixel values. By using SVD, a fundamental concept from linear algebra, we can significantly compress these images without a substantial loss in quality. Companies and platforms handling vast amounts of image data benefit from such techniques to save storage space and reduce transfer times.
- Recommendation Systems: Ever wondered how platforms like Netflix or Spotify seem to know your taste? At the heart of these recommendation engines lie gigantic matrices filled with user-item interactions. By employing matrix factorization techniques and vector spaces, these platforms can predict what movie or song you’re likely to enjoy next.
- Natural Language Processing (NLP) & Word Embeddings: Representing words as vectors in high-dimensional space is a hallmark of modern NLP. Techniques like Word2Vec or GloVe take gigantic text corpora and produce word vectors that capture semantic meanings, all thanks to the magic of linear algebra.
By exploring these real-world applications and delving into the nuts and bolts of their implementation, it becomes clear how pervasive and instrumental linear algebra is in machine learning. Whether we’re compressing photos or predicting movie preferences, this mathematical toolset offers a powerful lens to view and solve problems.

Conclusion
My journey into the world of machine learning, like that of many others, began with intrigue, followed closely by an onslaught of mathematical concepts. Among these, one stood tall and unwavering: linear algebra. It’s been a guiding star, illuminating the intricacies of algorithms and their real-world applications.
From the representation of data as vectors and matrices to the optimization techniques that breathe life into our models, linear algebra remains a steadfast foundation. And why shouldn’t it? Whether we’re simplifying high-dimensional data, predicting stock market trends, or teaching a machine to recognize a cat from a dog, these mathematical tools weave their magic, time and again.
Key Takeaways
- Linear algebra is more than just a subject; it’s the language of machine learning.
- Vectors, matrices, and linear transformations are not just mathematical constructs, but the building blocks of algorithms.
- Real-world applications abound, translating abstract math into tangible solutions.
And as you stand at this juncture, having journeyed through the expanse of linear algebra and its significance in machine learning, I hope you’re inspired, informed, and invigorated. Dive deeper, explore further, and always keep the curiosity alive. And if you have insights, questions, or tales from your own journey, share them in the comments below. Because learning, just like machine learning, thrives best when it’s a collaborative endeavor.